
Hello everyone! After several months of working on this project, I am very pleased to finally be able to share the results.
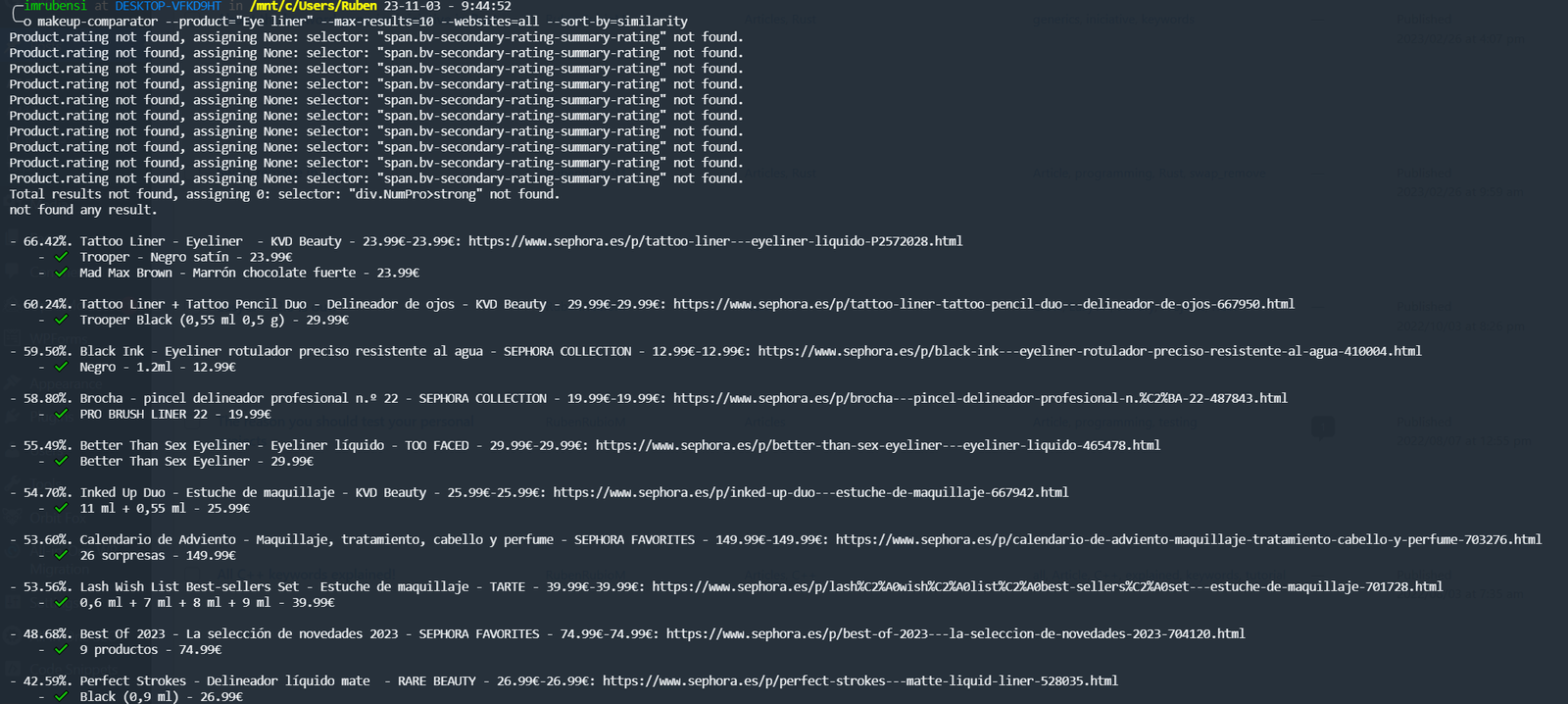
The makeup-Comparator project was initially intended to serve as both a backend for a website and a command-line interface (CLI). As of today, September 2023, only the CLI program has been released to offer users a quick method for searching for products across different websites and comparing them. This is achieved through web scraping techniques applied to various websites to extract their product data.
First and foremost, installing Makeup-Comparator is a straightforward process using Cargo. You can follow the instructions below:
cargo install makeup-comparatorAlso, you can find the entire repository in my Github.
After all, personal projects aren’t necessarily aimed at becoming a major success or a highly profitable service. In my case, I undertake them to learn and enhance my knowledge of various technologies and programming methods that I may not have the opportunity to explore in my daily work. That’s why I’d like to take this opportunity to explain what I’ve learned during this process and, perhaps more importantly, the challenges I’ve encountered along the way.
Rust
I chose Rust as the language for this project primarily because I wanted to delve deeper and learn more about this relatively new programming language, which I had previously used in other projects like: Easy_GA.
Rust allowed me to develop this project quite easily, thanks to its versatility and robustness. It is a language that makes it simple to start a project quickly and get things done efficiently.
Error handling is another powerful aspect of Rust. In this project, it was essential because web scraping relies heavily on whether we can retrieve the desired information or not, and it’s crucial to find solutions when this information is not available.
Testing
One of the most crucial aspects of this project was system testing, even more so than unit testing. This is significant because webpages can change frequently, and in a project that heavily relies on HTML structure, it was common to wake up one day and find that some parts of the web scraping were broken due to recent changes on the websites used to retrieve information.
Thanks to system testing, I was able to quickly identify the sources of these problems and address them promptly. It’s important to note that testing serves not only to ensure a high level of code reliability but also to define specific situations that, when altered, should trigger notifications or alerts.
Thanks to this project I also wrote an article about that: The reason you should test your personal projects.
Code coverage
Testing is indeed crucial, but its effectiveness depends on the coverage of the parts we expect to test. In this project, I paid special attention to the code coverage of my testing efforts. I designed a script to calculate the coverage generated by my tests and utilized various tools to visualize this information. I also set a goal of maintaining test coverage above 90% of the lines of code to ensure thorough testing.
The same way as with testing, this work gave me the idea of writing a article that was really popular online: Code coverage in Rust.
CI/CD
Continuous Integration/Continuous Deployment (CI/CD) pipelines are common in the industry but not often seen in personal projects. In my case, it was more about exploring this aspect and understanding what it could offer me.
Despite the fact that this project was developed by a single programmer (myself), I structured the repository to follow a Gitflow pattern of integration. I prohibited direct pushes to the master branch and enforced passing the tests defined by Github Actions before any changes were merged.
Before implementing the CI/CD pipeline, I established Git hooks to ensure that the code being pushed didn’t contain any warnings, didn’t fail static analysis, was well-formatted, and that all tests were passing.
You can find an article explaining more about that: What are Git Hooks and how to use them in Rust.
Deployment
Finally, the deployment process provided by Cargo is very straightforward and easy. I divided my project into two crates: one for web scraping, which can be reused in other projects, and the other for visualizing the results using the first crate.













