Projects Rust
Makeup-Comparator
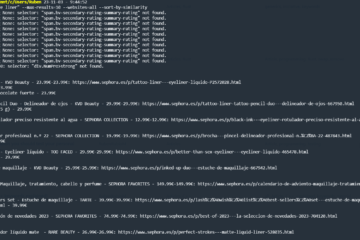
makeup-comparator is a CLI tool made with Rust that lets the user find and compare a product within a variety of cosmetic webpages
makeup-comparator is a CLI tool made with Rust that lets the user find and compare a product within a variety of cosmetic webpages

A guide to understand what code coverage is and how to use it in Rust

A quick introduction to setup git hooks in your rust projects

A discussion about the Keywords Generics iniciative in Rust



Explanation of how to implement different memory layouts in Rust programming language

Hello rustaceans! The version 1.1.0 for Easy_GA crate is finally out! As always you can find the repository in Github and the crate in crates.io The full CHANGELOG is avaliable in CHANGELOG.md [1.1.0] Logger The logger is a very usefull tool to measure and retrieve some data from the execution. Read more…

Crates: https://crates.io/crates/easy_ga Github repository: https://github.com/RubenRubioM/easy_ga Easy_GA is a genetic algorithm library made for Rust projects. It provides full customization for your own genotypes definitions and a genetic algorithm implementation to wrap all the common logic within a genetic algorithm. Features Usage In your Cargo.tml you have to add the Easy_GA Read more…